Handle Line Breaking With Fold and FMT Commands in Linux Terminal
Formatting text so the lines will fit in the available space on the target device are not that easy when it comes to the terminal. Instead of breaking lines by hand you can use the POSIX fold utility and the GNU/BSD fmt command to reflow a text so lines will not exceed a given length.
When you use a word processor, formatting text so the lines will fit in the available space on the target device should not be an issue. But when working at the terminal, things are not that easy.
Of course, you can always break lines by hand using your favorite text editor, but this is rarely desirable and it’s even out of the question for automated processing.
Hopefully, the POSIX fold utility and the GNU/BSD fmt command can help you to reflow a text so lines will not exceed a given length.
What’s a line in Unix, again?
Before going into the details of the fold and fmt commands, let’s define first what we are talking about. In a text file, a line is made of an arbitrary amount of characters, followed by the special newline control sequence (sometimes called EOL, for end-of-line)
On Unix-like systems, the end-of-line control sequence is made of the (one and only) character line feed, sometimes abbreviated LF or written \n following a convention inherited from the C language. At binary level, the line feed character is represented as a byte holding the 0a hexadecimal value.
You can easily check that using the hexdump utility we will use a lot in this article. So that may be a good occasion to familiarize yourself with that tool. You may, for example, examine the hexadecimal dumps below to find how many newline characters have been sent by each echo command. Once you think you have the solution, just retry those commands without the | hexdump -C part to see if you guessed it correctly.
sh$ echo hello | hexdump -C
00000000 68 65 6c 6c 6f 0a |hello.|
00000006
sh$ echo -n hello | hexdump -C
00000000 68 65 6c 6c 6f |hello|
00000005
sh$ echo -e 'hello\n' | hexdump -C
00000000 68 65 6c 6c 6f 0a 0a |hello..|
00000007Worth mentioning at this point different operating systems may follow different rules regarding the newline sequence. As we’ve seen above, Unix-like operating systems are using the line feed character, but Windows, like most Internet protocols, are using two characters: the carriage return+line feed pair (CRLF, or 0d 0a, or \r\n). On “classic” Mac OS (up to and including MacOS 9.2 in the early 2000s), Apple computers were using the CR alone as the newline character. Other legacy computers also used the LFCR pair, or even completely different byte sequences in the case of older ASCII-incompatible systems. Fortunately, those latter are relics of the past, and I doubt you will see any EBCDIC computer in use today!
Speaking of history, if you’re curious, the usage of the “carriage return” and “line feed” control characters date back to the Baudot code used in the teletype era. You may have seen teletype depicted in old movies as an interface to a room-sized computer. But even before that, teletypes were used “standalone” for point-to-point or multi-point communication. At that time, a typical terminal looked like a heavy typewriter with a mechanical keyboard, paper, and a mobile carriage holding the print head. To start a new line the carriage has to be brought back to the far left, and the paper has to move upward by rotating the platen (sometimes called the “cylinder”). Those two moves were controlled by two independent electromechanical systems, the line feed and carriage return control characters being directly wired to those two parts of the device. Since moving the carriage require more times than rotating the platen, it was logical to initiate the carriage return first. Separating the two functions also had a couple of interesting side effects, like allowing overprinting (by sending only the CR) or efficient transmission of “double interline” (one CR + two LF).
The definition at the start of this section mostly describes what a logical line is. Most of the time, however, that “arbitrarily long” logical line has to be sent on a physical device like a screen or a printer, where the available space is limited. Displaying short logical lines on a device having larger physical lines is not an issue. Simply there is unused space on the right of the text. But what if you try to display a line of text larger than the available space on the device? Actually, there are two solutions, each one with its share of drawbacks:
- First, the device can truncate the lines at its physical size, thus hiding part of the content to the user. Some printers do that, especially dumb printers (and yes, there are still basic dot matrix printers in use today, especially in harsh or dirty environments!)
- The second option to display long logical lines is to split them onto several physical lines. This is called line wrapping because lines seem to wrap around the available space, an effect particularly visible if you can resize the display like when working with a terminal emulator.
Those automatic behaviors are quite useful, but there are still times you want to break long lines at a given position regardless of the physical size of the device. For example, it may be useful because you want the line breaks to occur at the same position both on the screen and on the printer. Or because you want your text to be used in an application that does not perform line wrapping (for example, if you programmatically embed text in an SVG file). Finally, believe it or no, there are still a lot of communication protocols that impose a maximum line width in the transmissions, including popular ones like IRC and SMTP (if you ever saw the error 550 Maximum line length exceeded you know what I’m talking about). So there are plenty of occasions where you need to break long lines in smaller chunks. This is the job of the POSIX fold command.
The fold command
When used without any option, the fold command adds extra newline control sequences to ensure no line will exceed the 80 character limit. Just to make it clear, one line will at most contains 80 characters plus the newline sequence.
If you’ve downloaded the support material for that article, you can try that by yourself:
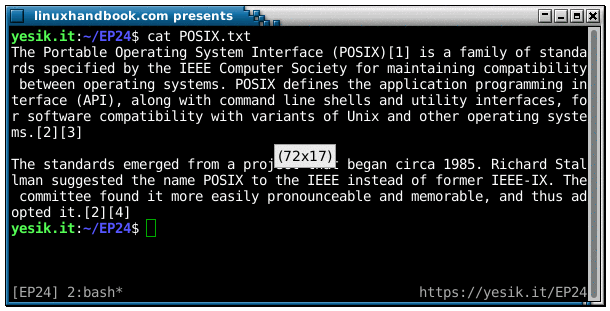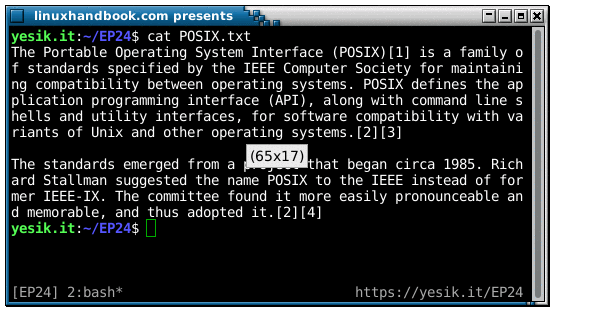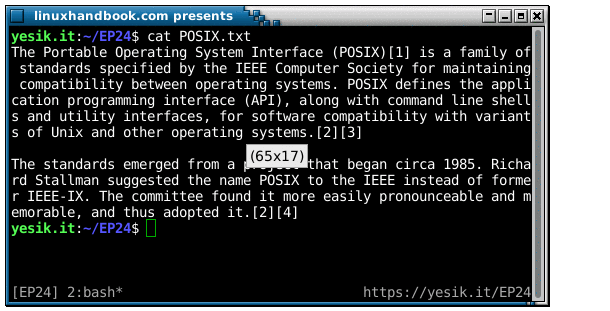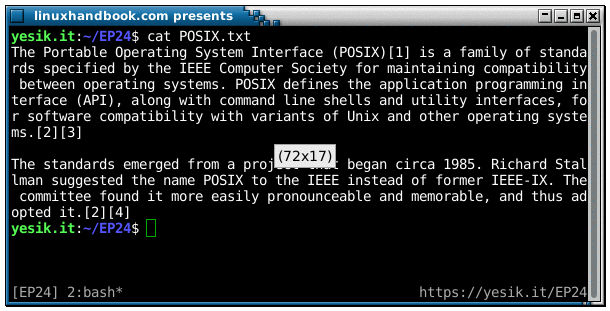
sh$ fold POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1] is a family of standards spec
ified by the IEEE Computer Society for maintaining compatibility between operati
ng systems. POSIX defines the application programming interface (API), along wit
h command line shells and utility interfaces, for software compatibility with va
riants of Unix and other operating systems.[2][3]
# Using AWK to prefix each line by its length:
sh$ fold POSIX.txt | awk '{ printf("%3d %s\n", length($0), $0) }'
80 The Portable Operating System Interface (POSIX)[1] is a family of standards spec
80 ified by the IEEE Computer Society for maintaining compatibility between operati
80 ng systems. POSIX defines the application programming interface (API), along wit
80 h command line shells and utility interfaces, for software compatibility with va
49 riants of Unix and other operating systems.[2][3]
0
80 The standards emerged from a project that began circa 1985. Richard Stallman sug
80 gested the name POSIX to the IEEE instead of former IEEE-IX. The committee found
71 it more easily pronounceable and memorable, and thus adopted it.[2][4]You can change the maximum output line length by using the -w option. More interesting probably is the use of the -s option to ensure lines will break at a word boundary. Let’s compare the result without and with the -s option when applied to the second paragraph of our sample text:
# Without `-s` option: fold will break lines at the specified position
# Broken lines have exactly the required width
sh$ awk -vRS='' 'NR==2' POSIX.txt |
fold -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
30 The standards emerged from a p
30 roject that began circa 1985.
30 Richard Stallman suggested the
30 name POSIX to the IEEE instea
30 d of former IEEE-IX. The commi
30 ttee found it more easily pron
30 ounceable and memorable, and t
21 hus adopted it.[2][4]
# With `-s` option: fold will break lines at the last space before the specified position
# Broken lines are shorter or equal to the required width
awk -vRS='' 'NR==2' POSIX.txt |
fold -s -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
29 The standards emerged from a
25 project that began circa
23 1985. Richard Stallman
28 suggested the name POSIX to
27 the IEEE instead of former
29 IEEE-IX. The committee found
29 it more easily pronounceable
24 and memorable, and thus
17 adopted it.[2][4]Obviously, if your text contains words longer than the maximum line length, the fold command will not be able to honor the -s flag. In that case, the fold utility will break oversized words at the maximum position, always ensuring no line will exceed the maximum allowed width.
sh$ echo "It's Supercalifragilisticexpialidocious!" | fold -sw 10
It's
Supercalif
ragilistic
expialidoc
ious!Multibyte characters
Like most, if not all, core utilities, the fold command was designed at a time one character was equivalent to one byte. However, this is no longer the case in modern computing, especially with the widespread UTF-8 adoption. Something which leads to unfortunate issues:
# Just in case, check first the relevant locale
# settings are properly defined
debian-9.4$ locale | grep LC_CTYPE
LC_CTYPE="en_US.utf8"
# Everything is OK, unfortunately...
debian-9.4$ echo élève | fold -w2
é
l�
�v
eThe word “élève” (the French word for “student”) contains two accented letters: é (LATIN SMALL LETTER E WITH ACUTE) and è (LATIN SMALL LETTER E WITH GRAVE). Using the UTF-8 character set those letters are encoded using two bytes each (respectively, c3 a9 and c3 a8), instead of only one byte as it is the case for non-accented Latin letters. You can check that by examining the raw bytes using the hexdump utility. You should be able to pinpoint the byte sequences corresponding to the é and è characters. By the way, you may also see in that dump our old friend the line feed character whose hexadecimal code was mentioned earlier:
debian-9.4$ echo élève | hexdump -C
00000000 c3 a9 6c c3 a8 76 65 0a |..l..ve.|
00000008Let’s examine now the output produced by the fold command:
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000bObviously, the result produced by the fold command is slightly longer than the original string of character because of the extra newlines: respectively 11 bytes long and 8 bytes long, including the newlines. Speaking of that, in the output of the fold command you may have seen the line feed (0a) character appearing every two bytes. And this is exactly the problem: the fold command broke lines at byte positions, not at character positions. Even if that break occurs in the middle of a multi-byte character! No need to mention the resulting output is no longer a valid UTF-8 byte stream, hence the use of the Unicode Replacement Character (�) by my terminal as a placeholder for the invalid byte sequences.
Like for the cut command I wrote about a few weeks ago, this is a limitation in the GNU implementation of the fold utility and this is clearly in opposition with the POSIX specifications which explicitly states that “A line shall not be broken in the middle of a character.”
So it appears the GNU fold implementation only deals properly with fixed-length one-byte character encodings (US-ASCII, Latin1, and so on). As a workaround, if a suitable character set exists, you may transcode your text to a one-byte character encoding before processing it, and transcode it back to UTF-8 afterward. However, this is cumbersome, to say the least:
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000a
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1
él
èv
eAll that being quite disappointing, I decided to check the behavior of other implementations. As it is often the case, the OpenBSD implementation of the fold utility is much better in that matter since it is POSIX compliant and will honor the LC_CTYPE locale setting to properly handle multi-byte characters:
openbsd-6.3$ locale | grep LC_CTYPE
LC_CTYPE=en_US.UTF-8
openbsd-6.3$ echo élève | fold -w 2 C
él
èv
e
openbsd-6.3$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000aAs you can see, the OpenBSD implementation properly cut lines at character positions, regardless of the number of bytes needed to encode them. In the overwhelming majority of the use cases, this is what you want. However if you need the legacy (i.e.: GNU style) behavior considering one byte as one character, you can temporarily change the current locale to the so-called POSIX locale (identified by the constant “POSIX” or, for historical reasons, “C”):
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2
é
l�
�v
e
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000bFinally, POSIX specifies the -b flag, which instructs the fold utility to measure line length in bytes, but that nevertheless guarantees multi-byte characters (according to the current LC_CTYPE locale settings) will not be broken.
As an exercise, I strongly encourage you to take the time needed to find the differences at byte-level between the result obtained by changing the current locale to “C” (above), and the result obtained by using the -b flag instead (below). It may be subtle. But there is a difference:
openbsd-6.3$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c 0a c3 a8 0a 76 65 0a |...l....ve.|
0000000bSo, did you find the difference?
Well, by changing the locale to “C”, the fold utility didn’t take any care of the multi-byte sequences— since, by definition, when the locale is “C” the tools must assume one character is one byte. So a newline may be added anywhere, even in the middle of a sequence of bytes that would have been considered as a multi-byte character in another character encoding. This is exactly what happened when the tool produced the c3 0a a8 byte sequence: The two bytesc3 a8 are understood as one character when LC_CTYPE defines the character encoding to be UTF-8. But the same sequence of bytes is seen as two characters in the “C” locale:
# Bytes are bytes. They don't change so
# the byte count is the same whatever is the locale
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -c)
2 bytes
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=C wc -c)
2 bytes
# The interpretation of the bytes may change depending on the encoding
# so the corresponding character count will change
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -m)
1 chars
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=C wc -m)
2 charsOn the other hand, with the -b option, the tool should still be multi-byte aware. That option only changes is the way it counts positions, in bytes this time, rather than in characters as it is by default. In that case, since multi-bytes sequences are not broken up, the resulting output remains a valid character stream (according to the current LC_CTYPE locale settings):
openbsd-6.3$ echo élève | fold -b -w 2
é
l
è
veYou’ve seen it, no more occurrences now of the Unicode Replacement Character (�), and we didn’t lose any meaningful character in the process— at the expense of ending up this time with lines containing a variable number of characters and a variable number of bytes. Finally, all the tool ensures is there are no more bytes per line than requested with the -w option. Something we can check using the wc tool:
openbsd-6.3$ echo élève | fold -b -w 2 | while read line; do
> printf "%3d bytes %3d chars %s\n" \
> $(echo -n $line | wc -c) \
> $(echo -n $line | wc -m) \
> $line
> done
2 bytes 1 chars é
1 bytes 1 chars l
2 bytes 1 chars è
2 bytes 2 chars veOnce again, take the time needed to study the example above. It makes use of the printf and wc commands I didn’t explain in detail previously. So, if things are not clear enough, don’t hesitate to use the comment section to ask for some explanations!
Out of curiosity, I checked the -b flag on my Debian box using the GNU fold implementation:
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
debian-9.4$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000bDon’t spend your time trying to find a difference between the -b and non--b versions of that example: we’ve seen the GNU fold implementation is not multi-byte aware, so both results are identical. If you’re not convinced of that, maybe you could use the diff -s command to let your computer confirm it. If you do it, please use the comment section to share the command you used with the other readers!
Anyway, does that mean the -b option useless in the GNU implementation of the fold utility? Well, by reading more carefully the GNU Coreutils documentation for the fold command, I found the -b option only deals with special characters like the tab or backspace which respectively count for 1~8 (one to eight) or -1 (minus one) position in normal mode, but they always count for 1 position in the byte mode. Confusing? So, maybe we could take some time to explain that in more details.
Tab and backspace handling
Most of the text files you will deal with only contain printable characters and end of line sequences. However, occasionally, it may happen some control characters find their way into your data. The tab character (\t) is one of them. Much more rarely, the backspace (\b) may also be encountered. I still mention it here because, as it names implies, it’s a control character that makes the cursor moving one position backward (toward the left), whereas most of the other characters are making it going forward (toward the right).
sh$ echo -e 'tab:[\t] backspace:[\b]'
tab:[ ] backspace:]This may be not visible in your browser, so I strongly encourage you to test that on your terminal. But the tab characters (\t) occupies several positions on the output. And the backspace? There seems to have something strange in the output, isn’t it? So let slow down things a little, by breaking the text string into several parts, and inserting some sleep between them:
# For that to work, type all the commands on the same line
# or using backslashes like here if you split them into
# several (physical) lines:
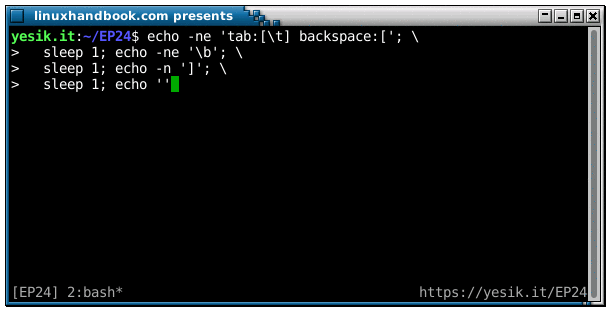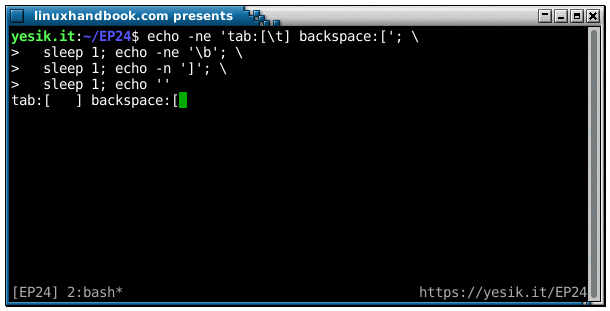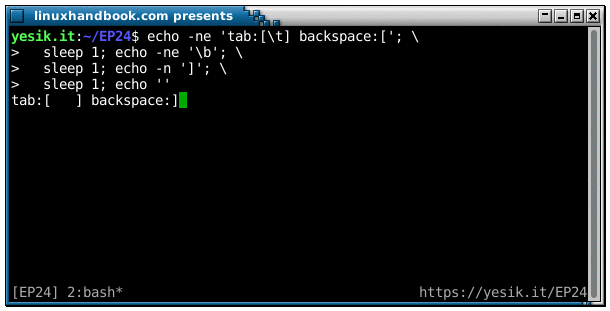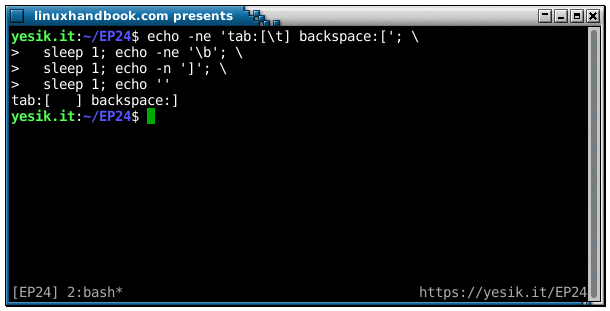
sh$ echo -ne 'tab:[\t] backspace:['; \
sleep 1; echo -ne '\b'; \
sleep 1; echo -n ']'; \
sleep 1; echo ''OK? Did you see it this time? Let’s decompose the sequence of the events:
- The first string of characters is displayed “normally” up to the second opening square bracket. Because of the
-nflag, theechocommand does not send a newline character, so the cursor stays on the same line. - First sleep.
- Backspace is issued, resulting in the cursor moving backward one position. Still no newline, so the cursor remains on the same line.
- Second sleep.
- The closing square bracket is displayed, overwriting the opening one.
- Third sleep.
- In the absence of the
-noption, the lastechocommand finally sends the newline character and the cursor move on the next line, where your shell prompt will be displayed.
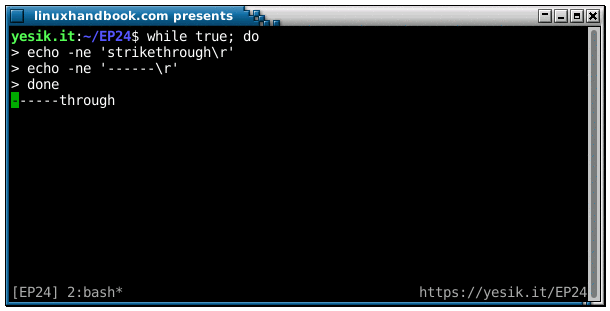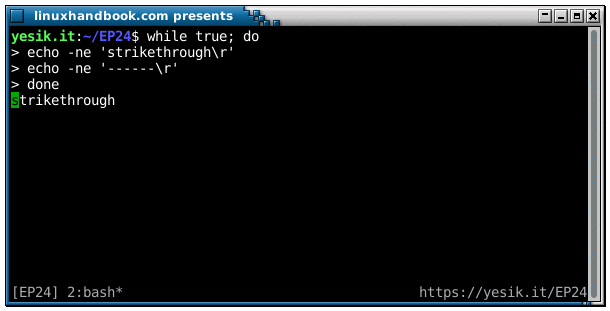
Of course, a similarly cool effect can be obtained using a carriage return, if you remember it:
sh$ echo -n 'hello'; sleep 1; echo -e '\rgood bye'
good byeI’m pretty sure you’ve already seen some command line utilities like curl and wget displaying a progress bar. They do their magic using a combination of \b and/or \r.
For interesting that discussion can be by itself, the point here was to understand that handling those characters can be challenging for the fold utility. Hopefully, the POSIX standard defines the rules:
<backspace> The current count of line width shall be decremented by one, although the count never shall become negative. The fold utility shall not insert a <newline> immediately before or after any <backspace>. <carriage-return> The current count of line width shall be set to zero. The fold utility shall not insert a <newline> immediately before or after any <carriage-return>. <tab> Each <tab> encountered shall advance the column position pointer to the next tab stop. Tab stops shall be at each column position n such that n modulo 8 equals 1. _
All those special treatments are disabled when using the -b option. In that case, the control characters above all count (correctly) for one byte and thus increase the position counter by one and only one— just like any other characters.
For a better understanding, I let you investigate by yourself the two following two examples (maybe using the hexdump utility). You should now be able to find why “hello” has become “hell” and where exactly is the “i” in the output (as it is there, even if you can’t see it!) As always, if you need help, or simply if you want to share your findings, the comment section is yours.
# Why "hello" has become "hell"? where is the "i"?
sh$ echo -e 'hello\rgood bi\bye' | fold -w4
hell
good
bye
# Why "hello" has become "hell"? where is the "i"?
# Why the second line seems to be made of only two chars instead of 4?
sh$ echo -e 'hello\rgood bi\bye' | fold -bw4
hell
go
od b
yeOther limitations
The fold command we’ve studied until now was designed to break long logical lines into smaller physical lines, for formatting purposes notably.
That means it assumes each input line is self-contained and can be broken independently of the other lines. This is not always the case, however. For example, let’s consider that very important mail I received:
sh$ cat MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
sh$ awk '{ length>maxlen && (maxlen=length) } END { print maxlen }' MAIL.txt
81Obviously, lines were already broken to some fixed width. The awk command told me the maximum line width here was … 81 characters— excluding the new line sequence. Yes, that was sufficiently odd so that I double checked it: indeed the longest line has 80 printable characters plus one extra space at the 81st position and only after that there is the linefeed character. Probably IT people working on behalf of this chair “manufactuer” could take benefit of reading this article!
Anyway, assuming I would like to change the formatting of that email, I will have issues with the fold command because of the existing line breaks. I let you check the two commands below by yourself if you want, but none of them will work as expected:
sh$ fold -sw 100 MAIL.txt
sh$ fold -sw 60 MAIL.txtThe first one will simply do nothing since all lines are already shorter than 100 characters. Regarding the second command, it will break lines at the 60th position but keep already existing newline characters so that the result will be jagged. It will be particularly visible in the third paragraph:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fold -sw 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
53 We supply all kinds of wooden, resin and metal event
25 chairs, include chiavari
60 chairs, cross back chairs, folding chairs, napoleon chairs,
20 phoenix chairs, etc.The first line of the third paragraph was broken at position 53, which is consistent with our maximum width of 60 characters per line. However, the second line broke at position 25 because that newline character was already present in the input file. In other words, to properly resize the paragraphs, we need first to rejoin the lines before breaking them at the new target position.
You can use sed or awk to rejoin the lines. And as a matter of fact, as I mentioned it in the introductory video, that would be a good challenge for you to take. So don’t hesitate to post your solution in the comment section.
As for myself, I will follow an easier path by looking at the fmt command. Whereas not a POSIX standard command, it is available both in the GNU and BSD world. So there are good chances it will be usable on your system. Unfortunately, the lack of standardization will have some negative implications as we will see it later. But for now, let’s concentrate of the good parts.
The fmt command
The fmt command is more evolved than the fold command and has more formatting options. The most interesting part is it can identify paragraphs in the input file based on the empty lines. That means all lines up to the next empty line (or the end of the file) will be first joined together to form what I called earlier a “logical line” of the text. Only after that, the fmt command will break the text at the requested position.
Let’s see now what that will change when applied to the second paragraph of my example mail:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fmt -w 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
60 We supply all kinds of wooden, resin and metal event chairs,
59 include chiavari chairs, cross back chairs, folding chairs,
37 napoleon chairs, phoenix chairs, etc.Anecdotally, the fmt command accepted to pack one more word in the first line. But more interesting, the second line is now filled, meaning the newline character already present in the input file after the word “chiavari” (what’s this?) has been discarded. Of courses, things are not perfect, and the fmt paragraph detection algorithm sometimes triggers false positives, like in the greetings at the end of the mail (line 14 of the output):
sh$ fmt -w 60 MAIL.txt | cat -n
1 Dear friends,
2
3 Have a nice day! We are manufactuer for event chairs and
4 tables, more than 10 years experience.
5
6 We supply all kinds of wooden, resin and metal event chairs,
7 include chiavari chairs, cross back chairs, folding chairs,
8 napoleon chairs, phoenix chairs, etc.
9
10 Our chairs and tables are of high quality and competitively
11 priced. If you need our products, welcome to contact me;we
12 are happy to make you special offer.
13
14 Best Regards DorisI said earlier the fmt command was a more evolved text formatting tool than the fold utility. Indeed it is. It may not be obvious at first sight, but if you look carefully lines 10-11, you may notice it used two spaces after the dot— enforcing a most discussed convention of using two spaces at the end of a sentence. I will not go into that debate to know if you should or shouldn’t use two spaces between sentences but you have no real choice here: to my knowledge, none of the common implementations of the fmt command offer a flag to disable the double space after a sentence. Unless such an option exists somewhere and I missed it? If this is the case, I’ll be happy you make me know about that using the comment section: as a French writer, I never used the “double space” after a sentence…
More fmt options
The fmt utility is designed with some more formatting capabilities than the fold command. However, not being POSIX defined, there are major incompatibilities between the GNU and BSD options.
For example, the -c option is used in the BSD world to center the text whereas in GNU Coreutils’s fmt it enables the crown margin mode, “preserving the indentation of the first two lines within a paragraph, and align the left margin of each subsequent line with that of the second line. “
I let you experiment by yourself with the GNU fmt -c if you want. Personally, I find the BSD text centering feature more interesting to study because of some oddity: indeed, in OpenBSD, fmt -c will center the text according to the target width— but without reflowing it! So the following command will not work as you might have expected:
openbsd-6.3$ fmt -c -w 60 MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
DorisIf you really want to reflow the text for a maximum width of 60 characters and center the result, you will have to use two instances of the fmt command:
openbsd-6.3$ fmt -w 60 MAIL.txt | fmt -c -w60
Dear friends,
Have a nice day! We are manufactuer for event chairs and
tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs,
include chiavari chairs, cross back chairs, folding chairs,
napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively
priced. If you need our products, welcome to contact me;we
are happy to make you special offer.
Best Regards DorisI will not make here an exhaustive list of the differences between the GNU and BSD fmt implementations … essentially because all the options are different! Except of course the -w option. Speaking of that, I forgot to mention -N where N is an integer is a shortcut for -wN. Moreover you can use that shortcut both with the fold and fmt commands: so, if you were perseverent enough to read his article until this point, as a reward you may now amaze your friends by saving one (!) entire keystroke the next time you will use one of those utilities:
debian-9.4$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified
by the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1]
is a family of standards specified by the IEEE
Computer Society for maintaining compatibility
between operating systems. POSIX defines the
application programming interface (API), along
debian-9.4$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interfaceAs the final word, you may also notice in that last example the GNU and BSD versions of the fmt utility are using a different formatting algorithm, producing a different result. On the other hand, the simpler fold algorithm produces consistent results between the implementations. All that to say if portability is a premium, you need to stick with the fold command, eventually completed by some other POSIX utilities. But if you need more fancy features and can afford to break compatibility, take a look at the manual for the fmt command specific to your own system. And let us know if you discovered some fun or creative usage for those vendor-specific options!

Engineer by Passion, Teacher by Vocation. My goal is to share my enthusiasm for what I teach and prepare my students to develop their skills by themselves.